What is AVX512?
AVX512 (Advanced Vector eXtensions) is the 512-bit SIMD instruction set that follows from previous 256-bit AVX2/FMA3/AVX instruction set. Originally introduced by Intel with its “Xeon Phi” GPGPU accelerators – albeit in a somewhat different form – it has finally made it to its CPU lines with Skylake-X (SKL-X/EX/EP) – for now HEDT (i9) and Server (Xeon) – and hopefully to mainstream at some point.
Note it is rumoured the current Skylake (SKL)/Kabylake (KBL) are also supposed to support it based on core changes (widening of ports to 512-bit, unit changes, etc.) – nevertheless no public way of engaging them has been found.
AVX512 consists of multiple extensions and not all CPUs (or GPGPUs) may implement them all:
- AVX512F – Foundation – most floating-point single/double instructions widened to 512-bit. [supported by SKL-X, Phi]
- AVX512-DQ – Double-Word & Quad-Word – most 32 and 64-bit integer instructions widened to 512-bit [supported by SKL-X]
- AVX512-BW – Byte & Word – most 8-bit and 16-bit integer instructions widened to 512-bit [supported by SKL-X]
- AVX512-VL – Vector Length eXtensions – most AVX512 instructions on previous 256-bit and 128-bit SIMD registers [supported by SKL-X]
- AVX512-CD – Conflict Detection – loop vectorisation through predication [not supported by SKL-X but Phi]
- AVX512-ER – Exponential & Reciprocal – transcedental operations [not supported by SKL-X but Phi]
- more sets will be introduced in future versions
As with anything, simply doubling register width does not automagically increase performance by 2x (twice) as dependencies, memory load/store latencies and even data characteristics limit performance gains – some of which may require future arch or even tools to realise their true potential.
In this article we test AVX512 core performance; please see our other articles on:
- Intel Core i9 (SKL-X) CPU Performance
- Intel Core i9 (SKL-X) Cache & Memory Performance
- AVX512 Improvement for Icelake Mobile (i7-1065G7 ULV)
Native SIMD Performance
We are testing native SIMD performance using various instruction sets: AVX512, AVX2/FMA3, AVX to determine the gains the new instruction sets bring.
Results Interpretation: Higher values (GOPS, MB/s, etc.) mean better performance.
Environment: Windows 10 x64, latest Intel drivers. Turbo / Dynamic Overclocking was enabled on both configurations.
| Native Benchmarks | SKL-X AVX512 | SKL-X AVX2/FMA3 | Comments | |||
 |
||||||
 |
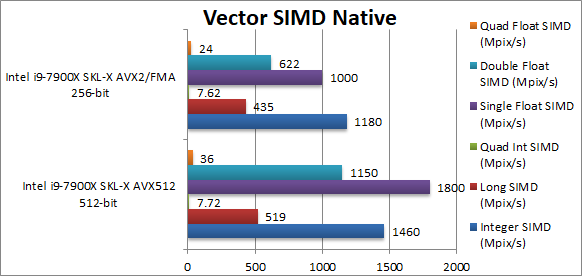
Native Integer (Int32) Multi-Media (Mpix/s) | 1460 [+23%] | 1180 | For integer workloads we manage only 23% improvement, not quite the 100% we were hoping but still decent. | ||
|
Native Long (Int64) Multi-Media (Mpix/s) | 519 [+19%] | 435 | With a 64-bit integer workload the improvement reduces to 19%. | ||
|
Native Quad-Int (Int128) Multi-Media (Mpix/s) | 7.72 [=] | 7.62 | No SIMD here | ||
|
Native Float/FP32 Multi-Media (Mpix/s) | 1800 [+80%] | 1000 | In this floating-point test we finally see the power of AVX512 – it is 80% faster than AVX2/FMA3 – a huge improvement. | ||
|
Native Double/FP64 Multi-Media (Mpix/s) | 1150 [+85%] | 622 | Switching to FP64 increases the improvement to 85% a huge gain. | ||
|
Native Quad-Float/FP128 Multi-Media (Mpix/s) | 36 [+50%] | 24 | In this heavy algorithm using FP64 to mantissa extend FP128 we see only 50% improvement still nothing to ignore. | ||
| AVX512 cannot bring 100% improvement but does manage up to 85% improvement – a no mean feat! While integer workload is only 20-25% it is still decent. Heavy compute algorithms will greatly benefit from AVX512. | ||||||
 |
||||||
 |
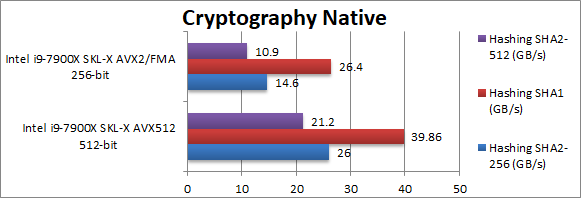
Crypto SHA2-256 (GB/s) | 26 [+78%] | 14.6 | With no data dependency – we get good scaling of almost 80% even with this integer workload. | ||
|
Crypto SHA1 (GB/s) | 39.8 [+51%] | 26.4 | Here we see only 50% improvement likely due to lack of (more) memory bandwidth – it likely would scale higher. | ||
|
Crypto SHA2-512 (GB/s) | 21.2 [+94%] | 10.9 | With 64-bit integer workload we see almost perfect scaling of 94%. | ||
| As we work on different buffers and have no dependencies, AVX512 brings up to 94% performance improvement – only limited by memory bandwidth with even 4 channel DDR4 @ 3200Mt/s not enough for 10C/20T CPU. AVX512 is absolutely worth it to drive the system to the limit. | ||||||
 |
||||||
 |
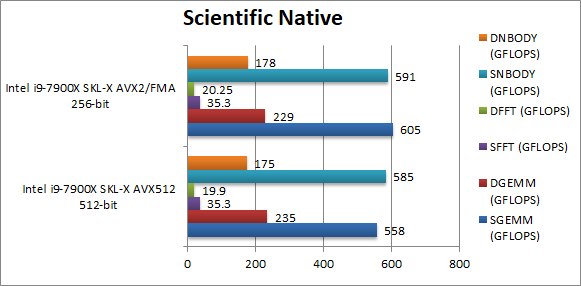
SGEMM (GFLOPS) float/FP32 | 558 [-7%] | 605 | Unfortunately the current compiler does not seem to help. | ||
|
DGEMM (GFLOPS) double/FP64 | 235 [+2%] | 229 | Changing to FP64 at least allows AVX512 to with by a meagre 2%. | ||
|
SFFT (GFLOPS) float/FP32 | 35.3 [=] | 35.3 | Again the compiler does not seem to help here. | ||
|
DFFT (GFLOPS) double/FP64 | 19.9 [-2%] | 20.2 | With FP64 nothing much happens. | ||
|
SNBODY (GFLOPS) float/FP32 | 585 [-1%] | 591 | No help from the compiler here either. | ||
|
DNBODY (GFLOPS) double/FP64 | 175 [-1%] | 178 | With FP64 workload nothing much changes. | ||
| With complex SIMD code – not written in assembler the compiler has some ways to go and performance is not great. But at least the performance is not worse. | ||||||
 |
||||||
 |
Blur (3×3) Filter (MPix/s) | 3830 [+60%] | 2390 | We start well here with AVX512 60% faster with float FP32 workload. | ||
|
Sharpen (5×5) Filter (MPix/s) | 1700 [+70%] | 1000 | Same algorithm but more shared data improves by 70%. | ||
|
Motion-Blur (7×7) Filter (MPix/s) | 885 [+56%] | 566 | Again same algorithm but even more data shared now brings the improvement down to 56%. | ||
|
Edge Detection (2*5×5) Sobel Filter (MPix/s) | 1290 [+56%] | 826 | Using two buffers does not change much still 56% improvement. | ||
|
Noise Removal (5×5) Median Filter (MPix/s) | 136 [+59%] | 85 | Different algorithm keeps the AVX512 advantage the same at about 60%. | ||
|
Oil Painting Quantise Filter (MPix/s) | 65.6 [+31.7%] | 49.8 | Using the new scatter/gather in AVX512 still brings 30% better performance. | ||
|
Diffusion Randomise (XorShift) Filter (MPix/s) | 3920 [+3%] | 3800 | Here we have a 64-bit integer workload algorithm with many gathers with AVX512 likely memory latency bound thus almost no improvement. | ||
|
Marbling Perlin Noise 2D Filter (MPix/s) | 770 [+2%] | 755 | Again loads of gathers does not allow AVX512 to shine but still decent performance | ||
| As with other SIMD tests, AVX512 brings between 60-70% performance increase, very impressive. However in algorithms that involve heavy memory access (scatter/gather) we are limited by memory latency and thus we see almost no delta but at least it is not slower. | ||||||
SiSoftware Official Ranker Scores
Final Thoughts / Conclusions
It is clear that even for a 1st-generation CPU with AVX512 support, SKL-X greatly benefits from the new instruction set – with anything between 50-95% performance improvement. However compiler/tools are raw (VC++ 2017 only added support in the recent 15.3 version) and performance sketchy where hand-crafted assembler is not used. But these will get better and future CPU generations (CFL-X, etc.) will likely improve performance.
Also let’s remember that some SKUs have 2x FMA (aka 512-bit) (and other instructions) licence – while most SKUs have only 1x FMA (aka 256-bit); the former SKUs likely benefit even more from AVX512 and it is something Intel may be more generous in enabling in future generations.
In algorithms heavily dependent on memory bandwidth or latency AVX512 cannot work miracles, but at least will extract the maximum possible compute performance from the CPU. SKUs with lower number of cores (8, 6, 4, etc.) likely to gain even more from AVX512.
We are eagerly awaiting the AVX512-enabled processors on desktop and mobile platforms…